Bagian 1: Kenapa Ekstraksi Data PDF Masih Jadi Mimpi Buruk di 2026
Meski sudah era AI, ekstraksi data dari PDF dan scan tetap jadi salah satu masalah paling bandel di perusahaan Indonesia. Invoice vendor dikirim sebagai PDF hasil scan, SPK dari klien dalam format Word yang di-print lalu di-scan ulang, arsip kontrak 10 tahun terakhir berupa folder scan tanpa teks searchable.
Saat tim finance butuh cari "invoice dari vendor X bulan Maret 2025", mereka harus buka folder, scroll satu per satu, bahkan kadang membandingkan stempel untuk memastikan itu dokumen yang benar. Ini bukan masalah teknologi lawas - ini terjadi di perusahaan yang sudah punya ERP modern.
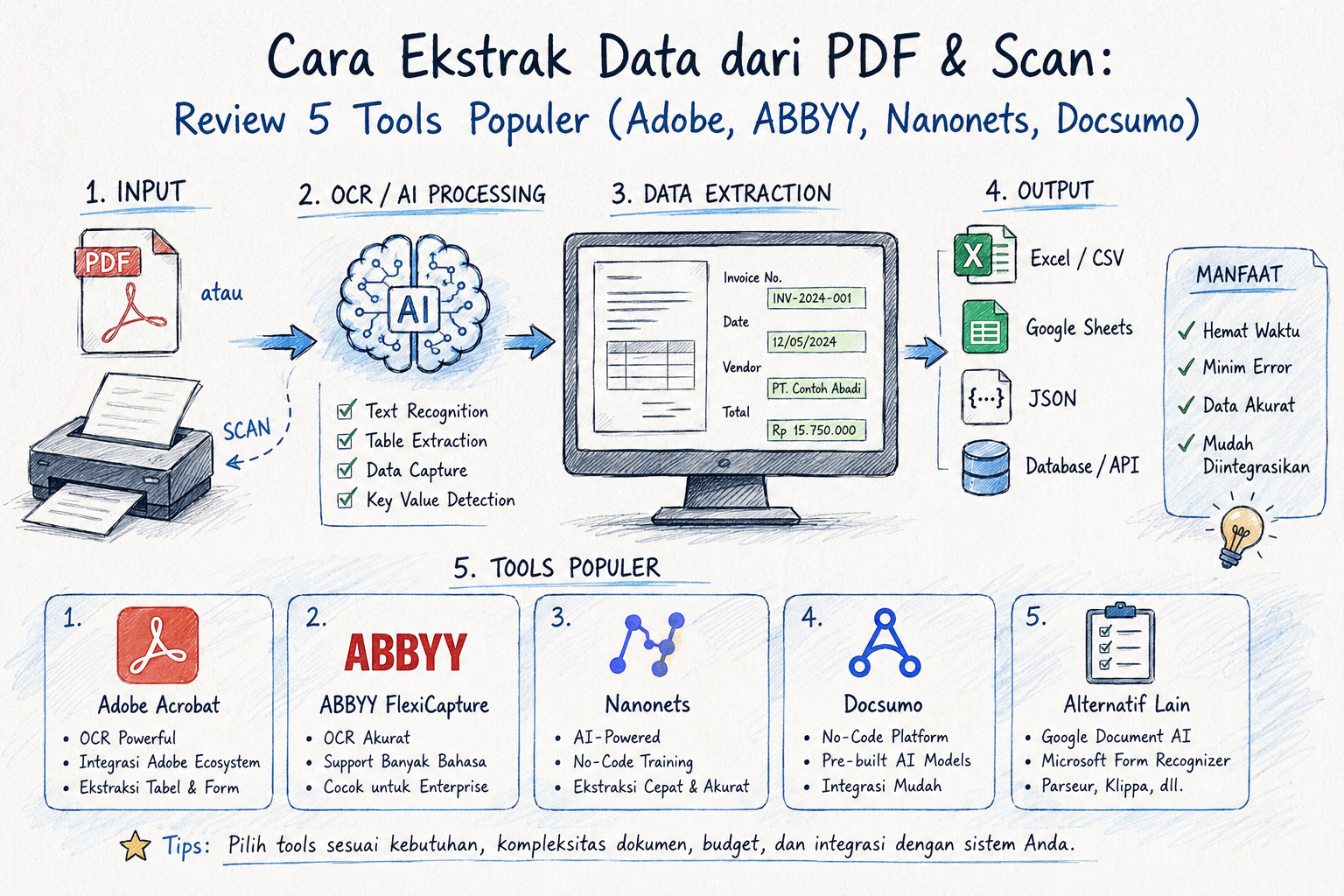
Solusinya selalu sama: tools OCR + ekstraksi data terstruktur. Tapi memilih tools yang tepat tidak sederhana.
Bagian 2: Review Fair 5 Tools Ekstraksi PDF Populer
Adobe Acrobat Pro DC - Rp 350 ribu/bulan per user. Unggul untuk OCR dokumen teks biasa (buku, laporan, artikel). Fitur "Export to Excel" bisa langsung mengubah tabel PDF menjadi spreadsheet. Kelemahan: tidak dirancang untuk ekstraksi data terstruktur (invoice, KTP, faktur pajak). Akurasi turun drastis pada scan kualitas rendah atau dokumen Bahasa Indonesia dengan stempel.
ABBYY FineReader PDF 16 - Sekitar Rp 2,5 juta untuk lisensi standalone. Salah satu engine OCR terbaik secara teknis, akurasi tinggi termasuk untuk script non-Latin. Bisa handle tabel kompleks dengan baik. Kelemahan: model lisensi per device, tidak ideal untuk high-volume, dan setup ekstraksi data terstruktur butuh template manual yang memakan waktu.
Nanonets - Mulai USD 499/bulan. Pendekatan modern berbasis AI - user upload contoh dokumen, tandai field yang diinginkan, dan model belajar otomatis. Cocok untuk ekstraksi invoice, receipt, purchase order dalam volume menengah-besar. Kelemahan: butuh training data awal yang cukup, dan bahasa Indonesia masih kalah akurat dibanding Inggris.
Docsumo - Mulai USD 500/bulan. Fokus khusus pada dokumen keuangan - invoice, bank statement, tax form. API-first, mudah diintegrasikan ke sistem akuntansi. Kelemahan: library template untuk dokumen Indonesia (SPT, e-Faktur, SKB) masih terbatas dan sering butuh konfigurasi kustom.
Rossum - Harga by quote, enterprise-focused. Menggunakan "cognitive data capture" yang bisa memahami invoice tanpa template pre-defined. Akurasi tinggi dan fitur validation loop yang baik. Kelemahan: harga entry point tinggi (USD 15.000+ setahun), overkill untuk perusahaan menengah.
Pola yang muncul: tools global unggul secara teknologi, tapi semuanya punya blind spot yang sama - dokumen khas Indonesia. Faktur pajak dengan layout PER-03/PJ/2022, SK kepegawaian dengan stempel tiga warna, akta notaris dengan format tabel yang bervariasi antar notaris - ini bukan skenario yang mereka latih.
Bagian 3: Tantangan Spesifik Dokumen Indonesia
Tiga tantangan yang sering tidak tertangani baik oleh tools global:
Stempel dan tanda tangan yang overlap dengan teks - Di dokumen formal Indonesia, stempel basah sering menimpa angka NIP, nomor surat, atau tanggal. Engine OCR generik akan membaca "kabur" atau skip area tersebut.
Campuran format - tabel di dalam tabel, footer multi-kolom - Faktur pajak standar pemerintah, kwitansi dengan format daerah, atau laporan BUMN sering punya layout yang tidak standar secara internasional.
Kebutuhan tanya-jawab, bukan sekadar ekstraksi - Setelah di-OCR pun, user sering butuh tanya "cari surat yang isinya tentang kenaikan pangkat Pak Budi tahun 2020". Ini bukan ekstraksi field, tapi pencarian semantik. Tools ekstraksi klasik tidak mengcover ini.
Bagian 4: Pendekatan Berbeda - OCR + AI Chat dalam Satu Platform
Alih-alih memisahkan "ekstraksi" dan "pencarian", muncul kategori baru: Document Management System yang menggabungkan Smart OCR dengan AI Chat. User tidak hanya bisa meng-OCR dokumen, tapi juga bertanya ke koleksi dokumen layaknya bertanya ke asisten.
Salah satu yang dirancang khusus untuk konteks Indonesia adalah Arsip Pintar dari Technema Solutions. Smart OCR-nya dilatih pada dokumen khas pemerintahan & korporasi Indonesia (SK, SPK, kontrak, faktur pajak), sehingga lebih akurat pada kasus stempel & tanda tangan overlap. Setelah dokumen ter-index, user bisa tanya lewat chat: "tunjukkan semua SK mutasi pegawai tahun 2024 di Bidang Keuangan" - dan sistem akan mengembalikan dokumen yang relevan beserta kutipan yang menjawab pertanyaan.
Use case yang cocok: instansi pemerintah yang harus migrasi arsip fisik ASN (sesuai SE BKN No. 11/2025), perusahaan dengan volume kontrak & SPK besar, atau firma hukum dengan arsip berkas perkara puluhan tahun.
Kapan tools global tetap lebih baik? Jika use case Anda murni ekstraksi invoice untuk di-feed ke ERP tanpa kebutuhan pencarian semantik, Nanonets atau Docsumo dengan API langsung lebih simpel. Arsip Pintar berfokus pada case di mana dokumen itu sendiri jadi knowledge base, bukan sekadar sumber data numerik. Detail: technemasolutions.co.id/produk/arsip-pintar.
Bagian 5: Checklist Memilih Tools Ekstraksi PDF yang Tepat
Sebelum beli, pastikan Anda sudah menjawab:
Apa output yang sebenarnya dibutuhkan? Data terstruktur untuk ERP (Nanonets/Docsumo), dokumen searchable untuk arsip (Arsip Pintar/ABBYY), atau sekadar PDF editable (Adobe)?
Berapa volume dokumen per bulan? < 500 lembar cukup dengan Adobe/ABBYY. 500-10.000 perlu solution AI-based. > 10.000 butuh API + automation pipeline.
Bahasa & jenis dokumen? Jika 80% dokumen Anda berformat lokal (SK, faktur pajak, SPK instansi), prioritaskan tools yang di-train pada dataset Indonesia.
Apakah dokumen perlu bisa ditanyai, bukan hanya diekstrak? Jika ya, tools tradisional kurang, butuh platform yang menggabungkan OCR + search + AI chat.
Apakah ada compliance requirement? Untuk instansi pemerintah dengan data sensitif, deployment on-premise atau private cloud sering wajib - ini membatasi pilihan ke vendor yang menyediakannya.
Satu pesan terakhir: jangan beli tools berdasarkan demo dengan dokumen "ideal". Uji coba pakai 20-50 dokumen terburuk yang Anda punya (scan miring, stempel overlap, halaman robek). Tools yang lulus test ini adalah yang benar-benar berguna di operasional harian.